
Modalità Operative
Attualmente esistono due metodi principali per convalidare la catena di blocchi come client: nodi completi e client SPV. Altri metodi, come i metodi di fidelizzazione del server, non sono discussi in quanto non sono raccomandati.
Full Node
Il primo e più sicuro modello è quello seguito da Bitcoin Core, noto anche come client "thick" o "full chain". Questo modello di sicurezza assicura la validità della catena di blocchi scaricando e convalidando blocchi dal primo (blocco genesi) fino al blocco scoperto più recentemente. Così che si possa usare l'altezza di un particolare blocco per verificare la sincronizzazione del client della rete.
Affinché un cliente venga ingannato, un furfante dovrebbe fornire una cronologia completa della catena di blocchi alternativa che è di maggiore difficoltà dell'attuale catena "vera", che è computazionalmente dispendioso (se non impossibile) a causa del fatto che la catena con la prova più cumulativa del lavoro è per definizione la "vera" catena.
A causa della difficoltà computazionale richiesta per generare un nuovo blocco sulla punta della catena, la capacità di ingannare un nodo completo diventa molto costosa dopo 6 conferme. Questa forma di verifica è altamente resistente agli attacchi sybil: solo un peer di rete onesto è richiesto per ricevere e verificare lo stato completo della vera "block chain".
Verifica semplificata dei pagamenti (SPV)
Un approccio alternativo dettagliato nel documento Bitcoin originale è un client che scarica solo le intestazioni dei blocchi durante il processo di sincronizzazione iniziale e quindi richiede le transazioni dai nodi completi secondo necessità. Questo metodo scala in modo lineare con l'altezza della catena di blocchi a soli 80 byte per intestazione del blocco o fino a 4,2 MB all'anno, indipendentemente dalla dimensione totale del blocco.
Come descritto nel white paper, la radice di merkle nell'intestazione del blocco insieme a un ramo di merkle può provare al client SPV che la transazione in questione è incorporata in un blocco nella catena di blocchi. Questo non garantisce la validità delle transazioni che sono incorporate. Dimostra invece la quantità di lavoro necessaria per eseguire un attacco doppia spesa (double spend attack).
La profondità del blocco nella catena di blocchi corrisponde alla difficoltà cumulativa che è stata eseguita per costruire sopra quel particolare blocco. Il client SPV conosce la radice di merkle e le informazioni sulla transazione associate e richiede il relativo ramo merkle da un nodo completo. Una volta che il ramo merkle è stato recuperato, provando l'esistenza della transazione nel blocco, il client SPV può quindi cercare la profondità del blocco come proxy per la validità e la sicurezza delle transazioni. Il costo di un attacco a un utente da parte di un nodo malintenzionato che inserisce una transazione non valida aumenta con la difficoltà cumulativa generata in cima a quel blocco, poiché il solo nodo dannoso eseguirà il mining di questa catena forgiata.
Potenziali carenze dell'SPV
Se implementato in modo ingenuo, un client SPV presenta alcuni punti deboli importanti.
Innanzitutto, mentre il client SPV non può essere facilmente ingannato nel pensare che una transazione si trovi in un blocco quando non lo è, il contrario non è vero. Un nodo completo può semplicemente mentire per omissione, portando un client SPV a credere che una transazione non sia avvenuta. Questo può essere considerato una forma di Denial of Service. Una strategia di mitigazione consiste nel connettersi a un numero di nodi completi e inviare le richieste a ciascun nodo. Tuttavia, questo può essere vanificato dal partizionamento della rete o dagli attacchi Sybil, dal momento che le identità sono essenzialmente gratuite e possono richiedere un'ampiezza di banda. Bisogna fare attenzione per garantire che il cliente non sia tagliato fuori dai nodi onesti.
In secondo luogo, il client SPV richiede solo le transazioni dai nodi completi corrispondenti alle chiavi che possiede. Se il client SPV scarica tutti i blocchi e poi scarta quelli non necessari, questo può essere estremamente intenso in termini di larghezza di banda richiesta. Se vengono richiesti semplicemente ai nodi completi i blocchi con transazioni specifiche, ciò consente ai nodi completi una visualizzazione completa degli indirizzi pubblici che corrispondono all'utente. Questa è una grande perdita di privacy, e consente tattiche come Denial of Service per i clienti, gli utenti o gli indirizzi che sono sfavoriti da coloro che eseguono alcuni nodi completi. Un client potrebbe semplicemente spammare molte richieste di transazioni false, creando una grande pressione sul client SPV che potrebbe portare alla perdita dello scopo dei thin client.
Per mitigare quest'ultimo problema, i filtri Bloom sono stati implementati come metodo di offuscamento e compressione delle richieste di dati di blocco.
Filtri Bloom
Un filtro Bloom è una struttura di dati probabilistici efficiente sotto il profilo dello spazio che viene utilizzata per verificare l'appartenenza a un elemento. La struttura dei dati raggiunge una grande compressione dei dati a scapito di un prescritto tasso falso positivo.
Un filtro Bloom inizia come una serie di n bit tutti impostati su 0. Viene scelto un insieme di k funzioni casuali di hash, ognuna delle quali emette un singolo numero intero compreso tra 1 e n.
Quando si aggiunge un elemento al filtro Bloom, l'elemento viene cancellato con k volte separatamente e per ognuna delle k output, il corrispondente bit del filtro Bloom a quell'indice è impostato su 1.
La ricerca del filtro Bloom viene eseguita utilizzando le stesse funzioni hash di prima. Se tutti i k bit a cui si accede nel filtro bloom sono impostati su 1, ciò dimostra con alta probabilità che l'elemento si trova nell'insieme. Chiaramente, gli indici k avrebbero potuto essere impostati a 1 mediante l'aggiunta di una combinazione di altri elementi nel dominio, ma i parametri consentono all'utente di scegliere il tasso di falsi positivi accettabile.
La rimozione degli elementi può essere eseguita solo eliminando il filtro bloom e ricreandolo da zero.
Applicazione di filtri Bloom
Invece di visualizzare i tassi di falsi positivi come passività, vengono utilizzati per creare un parametro sintonizzabile che rappresenta il livello di privacy desiderato e il compromesso della larghezza di banda. Un client SPV crea il proprio filtro Bloom e lo invia a un nodo completo utilizzando il messaggio “filterload”, che imposta il filtro per le transazioni che si desidera effettuare. Il comando “filteradd” consente l'aggiunta dei dati desiderati al filtro senza la necessità di inviare un filtro Bloom completamente nuovo, mentre “filterclear” consente alla connessione di tornare ai meccanismi di scoperta dei blocchi standard. Se il filtro è stato caricato, i nodi completi invieranno una forma modificata di blocchi, denominata “Merkle Block”. Il Merkle Block è semplicemente l'intestazione del blocco con il ramo di merkle associato al filtro Bloom impostato.
Un client SPV non può solo aggiungere transazioni come elementi al filtro, ma anche chiavi pubbliche, dati da script di firma e script pubkey e altro. Ciò consente il rilevamento delle transazioni P2SH.
Se un utente è più attento alla privacy, può impostare il filtro Bloom per includere più falsi positivi, a scapito dell'ampiezza di banda aggiuntiva utilizzata per il rilevamento delle transazioni. Se un utente ha un budget ridotto di larghezza di banda, può impostare il tasso di falsi positivi su basso, sapendo che ciò consentirà ai nodi completi una chiara visione di quali transazioni sono associate al suo cliente.
Risorse: BitcoinJ, un'implementazione Java di Bitcoin basata sul modello di sicurezza SPV e sui filtri Bloom. Utilizzato nella maggior parte dei portafogli Android.
I filtri Bloom sono stati standardizzati per l'uso tramite BIP37. Esaminare il BIP per i dettagli di implementazione.
Rete P2P
Il protocollo di rete Bitcoin consente ai nodi completi (peer) di mantenere in modo collaborativo una rete peer-to-peer per lo scambio di blocchi e transazioni. I nodi completi scaricano e verificano ogni blocco e transazione prima di inoltrarli ad altri nodi. I nodi di archiviazione sono nodi completi che memorizzano l'intera blockchain e possono servire blocchi storici ad altri nodi. Esistono anche altri nodi completi che non memorizzano l'intera blockchain. Molti client SPV utilizzano anche il protocollo di rete Bitcoin per connettersi ai nodi completi.
Le regole di consenso non coprono il networking, quindi i programmi Bitcoin possono utilizzare reti e protocolli alternativi.
Per fornire esempi pratici della rete peer-to-peer di Bitcoin, questa sezione utilizza Bitcoin Core come nodo completo rappresentativo e BitcoinJ come client SPV rappresentativo. Entrambi i programmi sono flessibili, quindi viene descritto solo il comportamento predefinito. Inoltre, per la privacy, gli indirizzi IP effettivi nell'output di esempio di seguito sono stati sostituiti con gli indirizzi IP riservati di RFC5737.
Peer Discovery
Quando vengono avviati per la prima volta, i programmi non conoscono gli indirizzi IP di alcun nodo completo attivo. Per scoprire alcuni indirizzi IP, interrogano uno o più nomi DNS (chiamati semi DNS) codificati in Bitcoin Core e BitcoinJ. La risposta alla ricerca dovrebbe includere uno o più “DNS A Record” con gli indirizzi IP dei nodi completi che potrebbero accettare nuove connessioni in entrata. Ad esempio, utilizzando il comando “dig” di Unix:
;; QUESTION SECTION:
;seed.bitcoin.sipa.be. IN A
;; ANSWER SECTION:
seed.bitcoin.sipa.be. 60 IN A 192.0.2.113
seed.bitcoin.sipa.be. 60 IN A 198.51.100.231
seed.bitcoin.sipa.be. 60 IN A 203.0.113.183
[...]
I semi DNS sono gestiti dai membri della comunità Bitcoin: alcuni forniscono server di seed DNS dinamici che ottengono automaticamente indirizzi IP di nodi attivi analizzando la rete; altri forniscono semi DNS statici che vengono aggiornati manualmente e sono più propensi a fornire indirizzi IP per nodi inattivi. In entrambi i casi, i nodi vengono aggiunti al seed DNS se vengono eseguiti sulle porte Bitcoin predefinite di 8333 per mainnet o 18333 per testnet.
I risultati del seed DNS non sono autenticati e un operatore di seed malizioso o un hacker di rete man-in-the-middle può restituire solo gli indirizzi IP dei nodi controllati dall'attaccante, isolando un programma sulla propria rete e permettendo all'utente malintenzionato di alimentarlo con transazioni e blocchi fasulli. Per questo motivo, i programmi non dovrebbero fare affidamento esclusivamente sui semi DNS.
Una volta che un programma si è connesso alla rete, i suoi pari possono iniziare a inviare messaggi “addr” (indirizzo) con gli indirizzi IP e i numeri di porta di altri peer sulla rete, fornendo un metodo completamente decentralizzato di scoperta tra pari. Bitcoin Core conserva un record di peer noti in un database persistente su disco che in genere consente di collegarsi direttamente a quei peer all'avvio successivo senza dover utilizzare i seed DNS.
Tuttavia, i peer lasciano spesso la rete o cambiano gli indirizzi IP, quindi i programmi potrebbero dover effettuare diversi tentativi di connessione all'avvio prima che venga stabilita una connessione riuscita. Questo può aggiungere un ritardo significativo alla quantità di tempo necessario per connettersi alla rete, costringendo un utente ad attendere prima di inviare una transazione o controllare lo stato del pagamento.
Per evitare questo possibile ritardo, BitcoinJ utilizza sempre semi DNS dinamici per ottenere indirizzi IP per i nodi che si ritiene siano attualmente attivi. Bitcoin Core cerca anche di trovare un equilibrio tra ridurre al minimo i ritardi ed evitare inutili utilizzi di DNS: se Bitcoin Core ha voci nel suo database peer, spende fino a 11 secondi a tentare di connettersi ad almeno uno di essi prima di ricadere sui semi; se viene effettuata una connessione entro quel tempo, non richiede alcun seme.
Sia Bitcoin Core che BitcoinJ includono anche un elenco hardcoded di indirizzi IP e numeri di porta a diverse dozzine di nodi attivi nel periodo in cui la versione specifica del software è stata rilasciata per la prima volta. Bitcoin Core inizierà il tentativo di connettersi a questi nodi se nessuno dei server di seed DNS ha risposto a una query entro 60 secondi, fornendo un'opzione di fallback automatico.
Come opzione di fallback manuale, Bitcoin Core offre anche diverse opzioni di connessione da riga di comando, tra cui la possibilità di ottenere un elenco di peer da un nodo specifico tramite un indirizzo IP o di stabilire una connessione permanente a un nodo specifico tramite l'indirizzo IP. Vedi il testo -help per i dettagli. BitcoinJ può essere programmato per fare la stessa cosa.
Risorse:
Bitcoin Seeder, il programma gestito da molti dei semi utilizzati da Bitcoin Core e BitcoinJ.
https://github.com/sipa/bitcoin-seeder
La politica dei semi DNS di Bitcoin Core.
https://github.com/bitcoin/bitcoin/blob/master/doc/dnsseed-policy.md
L'elenco hardcoded degli indirizzi IP usati da Bitcoin Core e BitcoinJ viene generato utilizzando makeseeds script.
https://github.com/bitcoin/bitcoin/tree/master/contrib/seeds
Connessione ai peers
La connessione a un peer avviene inviando un messaggio “version”, che contiene il numero di versione, il blocco e l'ora corrente sul nodo remoto. Il nodo remoto risponde con il proprio messaggio “version”.
Quindi entrambi i nodi inviano un messaggio “verack” all'altro nodo per indicare che la connessione è stata stabilita.
Una volta connesso, il client può inviare al nodo remoto i messaggi “getaddr” e “addr” per raccogliere ulteriori peer.
Per mantenere una connessione con un peer, i nodi per impostazione predefinita invieranno un messaggio ai peer prima di 30 minuti di inattività. Se passano 90 minuti senza che un messaggio venga ricevuto da un peer, il client presumerà che la connessione sia stata chiusa.
Download iniziale del blocco
Prima che un nodo completo possa convalidare transazioni non confermate e blocchi recentemente estratti, deve scaricare e convalidare tutti i blocchi dal blocco 1 (il blocco dopo il blocco di genesi hardcoded) all'attuale punta della migliore catena di blocchi. Questo è il download iniziale del blocco (IBD) o la sincronizzazione iniziale.
Sebbene la parola "iniziale" implichi che questo metodo venga usato una sola volta, può anche essere utilizzato ogni volta che è necessario scaricare un gran numero di blocchi, ad esempio quando un nodo rilevato in precedenza è offline per un lungo periodo. In questo caso, un nodo può utilizzare il metodo IBD per scaricare tutti i blocchi che sono stati prodotti dall'ultima volta in cui era online.
Bitcoin Core utilizza il metodo IBD ogni volta che l'ultimo blocco sulla sua migliore catena di blocchi locale ha un tempo di intestazione del blocco più vecchio di 24 ore. Bitcoin Core 0.10.0 eseguirà anche IBD se la sua migliore catena di blocchi locale è più di 144 blocchi inferiore alla sua migliore catena di intestazione locale (cioè, la catena di blocchi locale è più di circa 24 ore nel passato).
Blocks-First
Bitcoin Core (fino alla versione 0.9.3) utilizza un semplice metodo di download a blocchi iniziali (IBD) che chiameremo blocks-first. L'obiettivo è scaricare i blocchi dalla migliore catena di blocchi in sequenza.
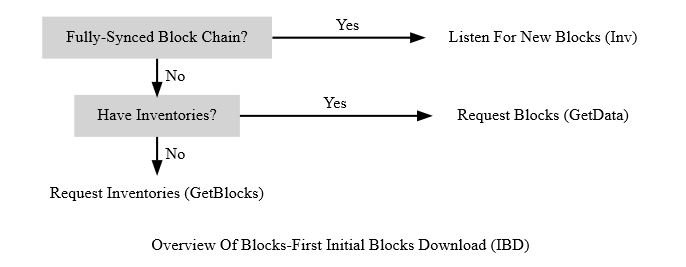
La prima volta che viene avviato un nodo, ha un solo blocco nella sua migliore block chain locale: il blocco genesis hardcoded (blocco 0). Questo nodo sceglie un peer remoto, chiamato nodo di sincronizzazione, e gli invia il messaggio “getblocks” illustrato di seguito.

Nel campo hash dell'header del messaggio getblocks, questo nuovo nodo invia l'hash dell'header dell'unico blocco che ha, il blocco genesis (6fe2 ... 0000 nell'ordine byte interno). Imposta inoltre il campo di hash di arresto su tutti gli zeri per richiedere una risposta di dimensioni massime.
Alla ricezione del messaggio “getblocks”, il nodo di sincronizzazione accetta il primo (e solo) hash dell'intestazione e cerca la sua migliore block chain locale per un blocco con quell'hash dell'intestazione. Trova che il blocco 0 corrisponde, quindi risponde con 500 inventari di blocchi (la risposta massima a un messaggio getblocks) a partire dal blocco 1. Invia questi inventari nel messaggio “inv” illustrato di seguito.

Gli inventari sono identificatori univoci per informazioni sulla rete. Ogni inventario contiene un campo “tipo” e l'identificativo univoco per un'istanza dell'oggetto. Per i blocchi, l'identificatore univoco è un hash dell'intestazione del blocco.
Gli inventari dei blocchi compaiono nel messaggio” inv” nello stesso ordine in cui appaiono nella catena di blocchi, quindi questo primo messaggio di “inv” contiene inventari per i blocchi da 1 a 501. (Ad esempio, l'hash del blocco 1 è 4860 ... 0000 come mostrato nell'illustrazione sopra.)
Il nodo IBD utilizza gli inventari ricevuti per richiedere 128 blocchi dal nodo di sincronizzazione nel messaggio “getdata” illustrato di seguito.


È importante per i nodi block-first che i blocchi vengano richiesti e inviati in ordine perché ogni intestazione di blocco fa riferimento all'hash dell'intestazione del blocco precedente. Ciò significa che il nodo IBD non può validare completamente un blocco finché non è stato ricevuto il suo blocco principale. I blocchi che non possono essere convalidati perché i loro genitori non sono stati ricevuti sono detti blocchi orfani; una sottosezione che segue li descrive in maggior dettaglio.
Alla ricezione del messaggio getdata, il nodo di sincronizzazione risponde con ciascuno dei blocchi richiesti. Ogni blocco viene inserito in un formato di blocco serializzato e inviato in un messaggio di blocco separato. Il primo messaggio di blocco inviato (per il blocco 1) è illustrato di seguito.
Il nodo IBD scarica ogni blocco, lo convalida e quindi richiede il blocco successivo non ancora richiesto, mantenendo una coda di massimo 128 blocchi da scaricare. Quando ha richiesto ogni blocco per il quale ha un inventario, invia un altro messaggio getblocks al nodo di sincronizzazione che richiede gli inventari massimo 500 blocchi in più. Questo secondo messaggio “getblocks” contiene diversi hash dell'intestazione, come illustrato di seguito:

Alla ricezione del secondo messaggio getblocks, il nodo di sincronizzazione cerca la migliore catena di blocchi locale per un blocco che corrisponde a uno degli hash dell'intestazione nel messaggio, provando ciascun hash nell'ordine in cui sono stati ricevuti. Se trova un hash corrispondente, risponde con 500 inventari di blocchi che iniziano con il blocco successivo da quel punto. Ma se non esiste un hash di corrispondenza (oltre all'hash di arresto), si presuppone che l'unico blocco che i due nodi hanno in comune sia il blocco 0 e quindi invia un “inv” che inizia con il blocco 1 (lo stesso messaggio di “inv” vede diverse illustrazioni sopra).
Questa ricerca ripetuta consente al nodo di sincronizzazione di inviare inventari utili anche se la catena di blocchi locale del nodo IBD è biforcata dalla catena di blocchi locale del nodo di sincronizzazione. Questo rilevamento del fork diventa sempre più utile quanto più il nodo IBD si avvicina alla punta della catena di blocchi.
Quando il nodo IBD riceve il secondo messaggio di “inv”, richiederà quei blocchi usando i messaggi “getdata”. Il nodo di sincronizzazione risponderà con i messaggi di blocco. Quindi il nodo IBD richiederà più inventari con un altro messaggio di “getblock” e il ciclo si ripeterà fino a quando il nodo IBD sarà sincronizzato con la punta della catena di blocchi. A quel punto, il nodo accetterà i blocchi inviati attraverso la normale trasmissione a blocchi descritta in una sottosezione successiva.
Blocks-First Vantaggi e svantaggi
Il vantaggio principale dei Block-first IBD è la sua semplicità. Lo svantaggio principale è che il nodo IBD si basa su un singolo nodo di sincronizzazione per tutto il suo download. Ciò ha diverse implicazioni:
•Limiti di velocità: tutte le richieste vengono fatte al nodo di sincronizzazione, quindi se il nodo di sincronizzazione ha larghezza di banda di upload limitata, il nodo IBD avrà velocità di download lente.
Nota: se il nodo di sincronizzazione non è in linea, Bitcoin Core continuerà il download da un altro nodo, ma verrà comunque scaricato solo da un singolo nodo di sincronizzazione alla volta.
•Riavvio Download: il nodo di sincronizzazione può inviare una catena di blocchi non ottimale (ma altrimenti valida) al nodo IBD. Il nodo IBD non sarà in grado di identificarlo come “non migliore” finché il download del blocco iniziale non sarà quasi completato, costringendo il nodo IBD a riavviare il download della catena di blocchi da un altro nodo. Bitcoin Core viene fornito con diversi punti di controllo della catena di blocchi a varie altezze del blocco selezionate dagli sviluppatori per aiutare un nodo IBD a rilevare che viene alimentato da cronologia della catena di blocchi alternativa, consentendo al nodo IBD di riavviare il download in precedenza nel processo.
•Attacchi di riempimento del disco: strettamente correlati al riavvio del download, se il nodo di sincronizzazione invia una catena di blocchi non ottimale (ma altrimenti valida), la catena verrà archiviata su disco, sprecando spazio e eventualmente riempiendo l'unità disco con dati inutili.
•Elevata memoria d'uso: sia malevolo che per errore, il nodo di sincronizzazione può inviare blocchi fuori ordine, creando blocchi orfani che non possono essere convalidati fino a quando i loro genitori non sono stati ricevuti e convalidati. I blocchi orfani vengono archiviati in memoria mentre attendono la convalida, il che può comportare un utilizzo elevato della stessa.
Tutti questi problemi sono affrontati in parte o completamente dal metodo IBD headers-first utilizzato in Bitcoin Core 0.10.0.
Risorse: la tabella seguente riepiloga i messaggi menzionati in questa sottosezione. I collegamenti nel campo del messaggio ti porteranno alla pagina di riferimento per quel messaggio.

Headers-First
Bitcoin Core 0.10.0 utilizza un metodo IBD (initial block download) chiamato headers-first. L'obiettivo è scaricare le intestazioni per la migliore catena di intestazione, convalidarle parzialmente nel miglior modo possibile e quindi scaricare i blocchi corrispondenti in parallelo. Questo risolve diversi problemi con il vecchio metodo block-first IBD.
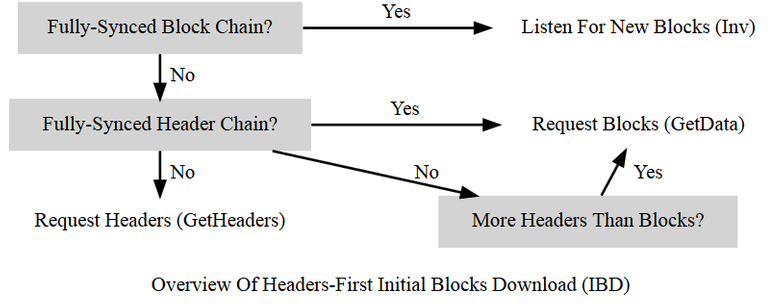
La prima volta che viene avviato un nodo, ha un solo blocco nella sua migliore blockchain locale: il blocco genesis hardcoded (blocco 0). Il nodo sceglie un peer remoto, che chiameremo nodo di sincronizzazione, e gli manda il messaggio “getheaders” illustrato di seguito.

Nel campo hash dell'intestazione del messaggio “getheaders”, il nuovo nodo invia l'hash dell'intestazione dell'unico blocco che ha, il blocco genesis (6fe2 ... 0000 nell'ordine byte interno). Imposta inoltre il campo di hash di arresto su tutti gli zeri per richiedere una risposta di dimensioni massime.
Alla ricezione del messaggio “getheaders”, il nodo di sincronizzazione accetta il primo (e solo) hash dell'intestazione e cerca la sua migliore blockchain locale per un blocco con quell'hash dell'intestazione. Trova che il blocco 0 corrisponde, quindi risponde con 2.000 header (la risposta massima) a partire dal blocco 1. Invia questi hash di intestazione nel messaggio di intestazione illustrato di seguito.

Il nodo IBD può parzialmente convalidare queste intestazioni di blocco garantendo che tutti i campi seguano le regole di consenso e che l'hash dell'intestazione sia inferiore alla soglia di destinazione in base al campo nBits. (La validazione completa richiede comunque tutte le transazioni dal blocco corrispondente.)
Dopo che il nodo IBD ha parzialmente convalidato le intestazioni dei blocchi, può fare due cose in parallelo:
Scarica altre intestazioni: il nodo IBD può inviare un altro messaggio getheaders al nodo di sincronizzazione per richiedere le prossime 2.000 intestazioni sulla migliore catena di intestazione. Tali intestazioni possono essere immediatamente convalidate e un altro batch viene richiesto ripetutamente finché non viene ricevuto un messaggio di intestazioni dal nodo di sincronizzazione con meno di 2.000 intestazioni, a indicare che non ha più intestazioni da offrire. Al momento della stesura, la sincronizzazione delle intestazioni può essere completata in meno di 200 round trip o circa 32 MB di dati scaricati.
Una volta che il nodo IBD riceve un messaggio di intestazioni con meno di 2.000 intestazioni dal nodo di sincronizzazione, invia un messaggio getheaders a ciascuno dei suoi peer in uscita per ottenere la loro visualizzazione della migliore catena di intestazione. Confrontando le risposte, può facilmente determinare se le intestazioni che ha scaricato appartengono alla migliore catena di intestazione riportata da uno dei suoi peer in uscita. Questo significa che un nodo di sincronizzazione disonesto verrà scoperto rapidamente anche se i punti di controllo non vengono utilizzati (a condizione che il nodo IBD si connetta ad almeno un peer onesto; Bitcoin Core continuerà a fornire checkpoint nel caso in cui colleghi onesti non possano essere trovati).
Scarica blocchi: mentre il nodo IBD continua a scaricare le intestazioni e dopo che le intestazioni hanno terminato il download, il nodo IBD richiederà e scaricherà ciascun blocco. Il nodo IBD può utilizzare gli hash di intestazione del blocco calcolati dalla catena di intestazione per creare messaggi getdata che richiedono i blocchi necessari per il loro inventario. Non è necessario richiederli dal nodo di sincronizzazione: può richiederli da qualsiasi dei suoi pari nodi completi. (Anche se non tutti i nodi completi possono memorizzare tutti i blocchi.) Ciò consente di recuperare blocchi in parallelo ed evitare di limitare la velocità di download alla velocità di upload di un singolo nodo di sincronizzazione.
Per distribuire il carico tra più peer, Bitcoin Core richiederà solo fino a 16 blocchi alla volta da un singolo peer. Combinato con il massimo di 8 connessioni in uscita, ciò significa che le header-first Bitcoin Core richiederà un massimo di 128 blocchi simultaneamente durante IBD (lo stesso numero massimo che blocca-prima Bitcoin Core richiesto dal suo nodo di sincronizzazione).
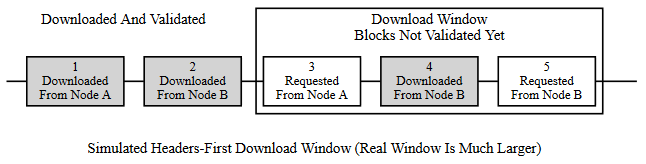
La prima modalità di intestazioni di Bitcoin Core utilizza una finestra di download mobile da 1.024 blocchi per massimizzare la velocità di download. Il blocco di altezza inferiore nella finestra è il blocco successivo da convalidare; se il blocco non è arrivato prima che Bitcoin Core sia pronto a convalidarlo, Bitcoin Core attenderà altri due secondi in più affinché il nodo di stallo invii il blocco. Se il blocco non è ancora arrivato, Bitcoin Core si disconnetterà dallo stallo e tenterà di connettersi a un altro nodo. Ad esempio, nell'illustrazione sopra, il nodo A verrà disconnesso se non invia il blocco 3 entro almeno due secondi.
Una volta che il nodo IBD è sincronizzato con la punta della catena di blocchi, accetta i blocchi inviati attraverso la normale trasmissione di blocchi descritta in una sottosezione successiva.
Risorse: la tabella seguente riepiloga i messaggi menzionati in questa sottosezione. I collegamenti nel campo del messaggio ti porteranno alla pagina di riferimento per quel messaggio.

Block Broadcasting
Quando un minatore scopre un nuovo blocco, trasmette il nuovo blocco ai suoi pari usando uno dei seguenti metodi:
Push blocco non richiesto: il minatore invia un messaggio di blocco a ciascuno dei suoi pari nodi completi con il nuovo blocco. Il minatore può ragionevolmente bypassare il metodo di inoltro standard in questo modo perché sa che nessuno dei suoi pari ha già il blocco appena scoperto.
Standard block relay: il minatore, agendo come nodo di inoltro standard, invia un messaggio di inv a ciascuno dei suoi pari (sia a livello di nodo completo che a SPV) con un inventario che fa riferimento al nuovo blocco. Le risposte più comuni sono:
Ogni peer block-first (BF) che vuole il blocco risponde con un messaggio getdata che richiede il blocco completo.
Ogni peer header-first (HF) che vuole il blocco risponde con un messaggio getheaders contenente l'hash dell'intestazione dell'intestazione high-height sulla sua migliore catena di intestazione, e probabilmente anche alcune intestazioni più indietro sulla migliore catena di intestazione per consentire il rilevamento di fork. Questo messaggio è immediatamente seguito da un messaggio getdata che richiede il blocco completo. Richiedendo per prima cosa le intestazioni, un peer di prime intestazioni può rifiutare i blocchi orfani come descritto nella sottosezione di seguito.
Ogni client di verifica dei pagamenti semplificata (SPV) che desidera che il blocco risponda con un messaggio getdata che richiede in genere un blocco di tipo merkle.
Il minatore risponde a ciascuna richiesta di conseguenza inviando il blocco in un messaggio di blocco, una o più intestazioni in un messaggio di intestazioni, o il merkle block e le transazioni relative al bloom filter del client SPV in un messaggio di merkleblock seguito da zero o più messaggi di tx.
Annuncio di intestazioni dirette: un nodo di inoltro può saltare l'overhead di andata e ritorno di un messaggio di invito seguito da getheader inviando invece immediatamente un messaggio di intestazioni contenente l'intestazione completa del nuovo blocco. Un peer HF che riceve questo messaggio convaliderà parzialmente l'intestazione del blocco come farebbe header-first IBD, quindi richiede il contenuto completo del blocco con un messaggio getdata se l'intestazione è valida. Il nodo relay risponde quindi alla richiesta getdata con i dati di blocco completi o filtrati in un messaggio block o merkleblock, rispettivamente. Un nodo HF potrebbe segnalare che preferisce ricevere le intestazioni anziché gli annunci inviando un messaggio speciale di sendheader durante l'handshake della connessione.
Questo protocollo per la trasmissione di blocchi è stato proposto nel BIP 130 ed è stato implementato in Bitcoin Core dalla versione 0.12.
Per impostazione predefinita, Bitcoin Core trasmette i blocchi utilizzando l'annuncio delle intestazioni dirette a tutti i peer che hanno segnalato con i sendheader e utilizza il relay block standard per tutti i peer che non lo hanno. Bitcoin Core accetta blocchi inviati utilizzando uno dei metodi sopra descritti.
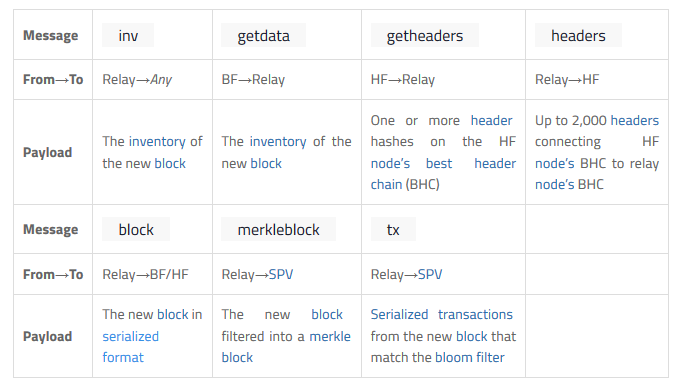
I nodi completi convalidano il blocco ricevuto e quindi lo pubblicizzano ai loro coetanei utilizzando il metodo del relè di blocco standard descritto sopra. La tabella condensata in basso evidenzia il funzionamento dei messaggi descritti sopra (Relay, BF, HF e SPV si riferiscono al nodo relay, un nodo blocks-first, un nodo headers-first e un client SPV; qualsiasi metodo di recupero dei blocchi.)
Blocchi orfani
I nodi Blocks-first possono scaricare blocchi orfani: blocchi il cui campo hash dell'intestazione del blocco precedente fa riferimento a un'intestazione di blocco che questo nodo non ha ancora visto. In altre parole, i blocchi orfani non hanno alcun genitore conosciuto (a differenza dei blocchi obsoleti, che hanno genitori noti ma che non fanno parte della migliore catena di blocchi).
Quando un nodo block-first scarica un blocco orfano, non lo convaliderà. Invece, invierà un messaggio getblocks al nodo che ha inviato il blocco orfano; il nodo trasmittente risponderà con un messaggio inv contenente gli inventari di qualsiasi blocco mancante al nodo di download (fino a 500); il nodo di download richiederà questi blocchi con un messaggio getdata; e il nodo di trasmissione invierà quei blocchi con un messaggio di blocco. Il nodo di download convaliderà tali blocchi e una volta che il genitore dell'ex blocco orfano sarà stato convalidato, convaliderà l'ex blocco orfano.
I nodi header-first evitano una parte di questa complessità richiedendo sempre le intestazioni di blocco con il messaggio getheaders prima di richiedere un blocco con il messaggio getdata. Il nodo di trasmissione invierà un messaggio di intestazioni contenente tutte le intestazioni di blocco (fino a 2.000) che ritiene che il nodo di download necessiti per raggiungere la punta della migliore catena di intestazione; ognuna di quelle intestazioni punterà al suo genitore, quindi quando il nodo di download riceve il messaggio di blocco, il blocco non dovrebbe essere un blocco orfano - tutti i suoi genitori dovrebbero essere noti (anche se non sono stati ancora convalidati). Se, nonostante ciò, il blocco ricevuto nel messaggio di blocco è un blocco orfano, un nodo header-first lo scarterà immediatamente.
Tuttavia, scartare orfani significa che i nodi headers-first ignoreranno i blocchi orfani inviati dai minatori in un push di blocco non richiesto.
Broadcasting delle transazioni
Per inviare una transazione a un peer, viene inviato un messaggio di inv. Se viene ricevuto un messaggio di risposta getdata, la transazione viene inviata utilizzando tx. Il peer che riceve questa transazione inoltra anche la transazione nello stesso modo, dato che si tratta di una transazione valida.
Pool di memoria
I peer completi possono tenere traccia delle transazioni non confermate che possono essere incluse nel blocco successivo. Questo è essenziale per i minatori che effettivamente mineranno alcune o tutte quelle transazioni, ma è anche utile per qualsiasi peer che voglia tenere traccia delle transazioni non confermate, come peer che offrono informazioni di transazione non confermate ai client SPV.
Poiché le transazioni non confermate non hanno uno stato permanente in Bitcoin, Bitcoin Core le archivia in una memoria non persistente, chiamandole pool di memoria o mempool. Quando un peer si spegne, il suo pool di memoria viene perso, ad eccezione delle transazioni memorizzate dal suo portafoglio. Ciò significa che le transazioni non confermate mai eliminate tendono a scomparire lentamente dalla rete quando i peer si riavviano o mentre eliminano alcune transazioni per fare spazio per gli altri.
Le transazioni che vengono estratte in blocchi che in seguito diventano blocchi obsoleti possono essere aggiunte nuovamente nel pool di memoria. Queste transazioni riaggiunte possono essere rimosse dal pool quasi immediatamente se i blocchi di sostituzione le includono. Questo è il caso di Bitcoin Core, che rimuove uno alla volta i blocchi obsoleti dalla catena, iniziando dalla punta (blocco più alto). Quando ogni blocco viene rimosso, le sue transazioni vengono aggiunte nuovamente al pool di memoria. Dopo aver rimosso tutti i blocchi obsoleti, i blocchi di sostituzione vengono aggiunti alla catena uno per uno, terminando con il nuovo tip. All'aggiunta di ogni blocco, tutte le transazioni confermate vengono rimosse dal pool di memoria.
I client SPV non dispongono di un pool di memoria per lo stesso motivo per cui non inoltrano le transazioni. Non possono verificare in modo indipendente che una transazione non sia ancora stata inclusa in un blocco e che spenda solo UTXO, in modo che non possano sapere quali transazioni sono idonee per essere incluse nel blocco successivo.
Nodi malfunzionanti
Prendi nota del fatto che per entrambi i tipi di trasmissione, sono in atto meccanismi per punire i peer malevoli che assorbono la larghezza di banda e risorse computazionali inviando false informazioni. Se un peer ottiene un banscore sopra la soglia -banscore = <n>, verrà bannato per il numero di secondi definito da -bantime = <n>, che per impostazione predefinita è 86.400 (24 ore).
Alert
-Rimosso in Bitcoin Core 0.13.0
Le versioni precedenti di Bitcoin Core consentivano agli sviluppatori e ai membri delle comunità fidate di emettere avvisi Bitcoin per informare gli utenti di problemi critici a livello di rete. Questo sistema di messaggistica è stato ritirato in Bitcoin Core v0.13.0; tuttavia, gli avvisi interni, gli avvisi di rilevamento delle partizioni e le funzionalità dell'opzione -alertnotify rimangono.

Copyright © 2017 - 2019 BTC-News.it All rights reserved
Network Status